信息处理与组织
Note
题型:名词解释(5x4)、论述(15x2)、编码(50,xml20, rdf20, owl10)
信息组织概述
信息组织、信息描述、信息揭示、元数据(五类)、DC
信息组织:信息组织是指利用一定的规则、方法和技术对信息的外部特征和内容特征进行描述和揭示,并按给定的参数和序列公式排列,使信息从无序集合转换为有序集合。
语义网:就是能根据语义进行判断的智能网络,实现人与电脑的无障碍沟通。
信息描述(著录):根据一定的描述规则和技术标准,对信息的外在特征和部分内容特征进行分析、选择和记录的过程。
信息揭示(标引):是在对信息的内容特征进行全面的、深层次分析与综合的基础上,根据特定的标引规则与工具,赋予信息内容特征以系统化代码或标识,以便将信息记录组织成概念标识系统的信息处理过程。
元数据:是描述其他数据的数据,或者说是用于提供某种资源的有关信息的结构化数据。
元数据标准:内容标准(RDA)、结构标准(DC)、显示标准(ISBD)、编码标准(MARC)、取值标准
DC修饰词:对元素进行限定和修饰,用来增加描述的准确性,分为元素限定词和编码体系修饰词。
元素限定词:元素限定词缩小了元素的含义范围,使其更具有专指性。
编码体系修饰词:有助于对所修饰术语值的理解,包括控制词表及正规的符号或解读方式。
RDA(Resource Description and Access, 资源描述与检索):一个元数据内容标准,提供一套用于形成支持资源发现的数据的规则和说明。
字符编码
字符编码和 URI、汉字编码字符集、GB2312
字节序:多字节数据在计算机内存中存储或者网络传输时各字节的存储顺序。
字符集:字符的合集,这些字符组成一套符号系统,可以组合起来形象的表达各种含义
编码字符集:字符以及对应的编码集合
字符编码:把字符集中的字符表示为二进制位的有序集合,以便再计算机中存储、传递和处理
美国标准信息交换标准码(ASCII),GBK,GB2312
统一资源标识符(URI):用来标识抽象或实体资源的简洁字符串。
国际化资源标识符(IRIs):基于通用字符集的字符序列
xml
标记语言和命名空间
<?xml version="1.0" encoding="UTF-8"?>
XML文档声明部分指明读取时所用的字符集,确保保存、读取时采用相同的字符集
每个XML都有一个且只能有一个根元素,只有注释和处理指令可以不包含在根元素中
<!--这是一个注释-->
<![CDATA[
这里的所有内容都会被XML解析器忽略
]]>
XML模式定义文件(Schema)
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
</xs:schema>
以.xsd为扩展名,属性xmlns:xs以url为值,该url声明其名称空间
通常使用一个简短的代号来代替URI,这个代号称为命名空间前缀(下面的river)
xmlns:river="http://www.myserver.com/"
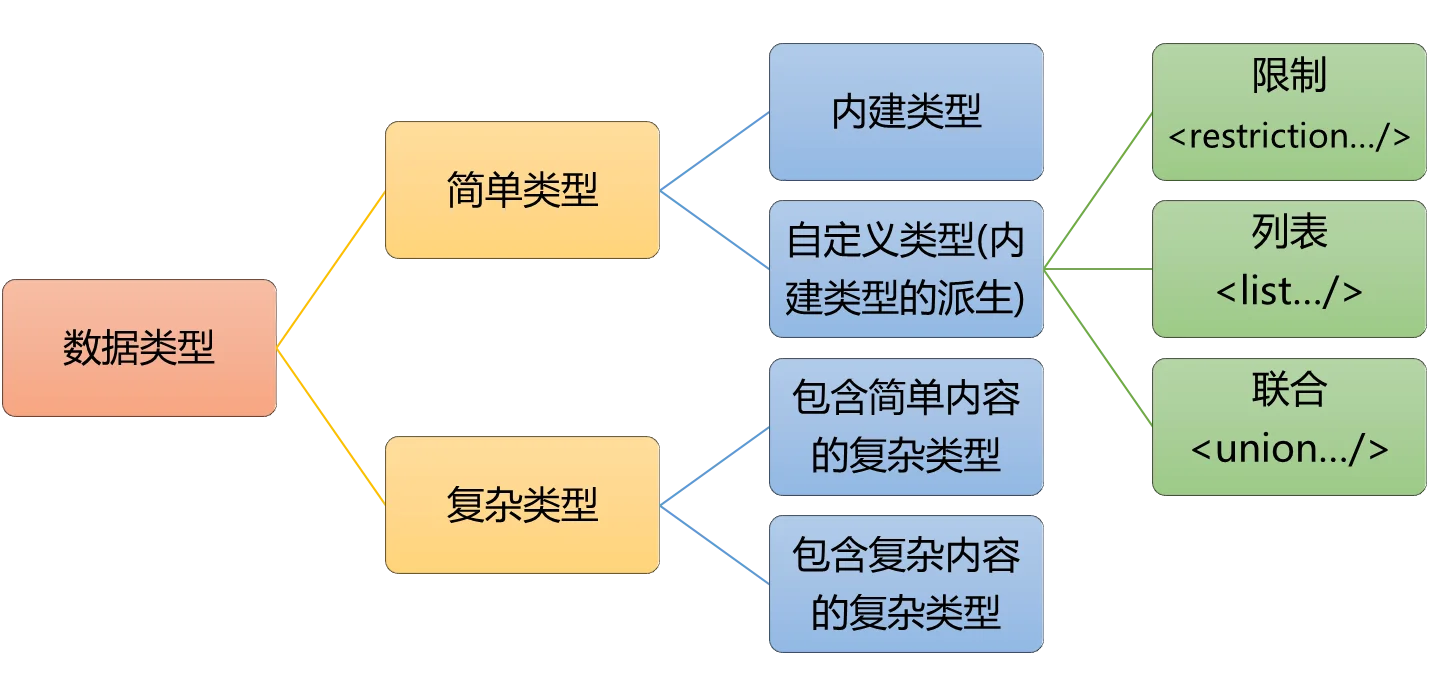
使用xs:element来定义需要使用的子元素,xs:element包含的属性有
name:用来定义元素名称,如:<xs:element name="student_id" />定义了<student_id />type:设置元素值的类型,可以是简单的和复杂的类型maxOccurs:设置元素可出现无数次,值为unbounded时,可以出现无数次
内建类型:如xs:string、xs:integer、xs:token等
restriction
自定义类型可以对内建类型进行一些派生,如对xs:integer进行派生,限制范围在300~500
<xs:simpleType>
<xs:restriction base=“xs:integer”>
<xs:maxInclusive value=“500”/>
<xs:minInclusive value=“300”/>
</xs:restriction>
</xs:simpleType>
minInclusive、maxInclusive、minExclusive、maxExclusive,对integer进行约束其中Inclusive是可以包含边界值的
length、minLength、maxLength,对string进行约束包含边界长度
totalDigits、fractionDigits对decimal进行约束,totalDigits指定最多可包含多少位数,fractionDigits指定最多可包含多少位小数
enumeration定义枚举约束,pattern定义正则表达式,whiteSpace空白处理
list
由单个数据类型扩展出列表类型,使用时必须指定列表元素的类型,有两种方式指定类型
<xs:simpleType name="age_list_Type">
<xs:list>
<xs:simpleType>
<xs:restriction base="xs:int">
<xs:minExclusive value="0"/>
<xs:maxExclusive value="100"/>
</xs:restriction>
</xs:simpleType>
</xs:list>
</xs:simpleType>
<xs:element name="age_list" type="age_list_Type"/>
<!-- OR -->
<xs:simpleType name="age_Type">
<xs:restriction base="xs:int">
<xs:minExclusive value="0"/>
<xs:maxExclusive value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="age_list_Type">
<xs:list itemType=“age_Type“/>
</xs:simpleType>
<xs:element name="age_list" type="age_list_Type"/>
<!-- XML文档: -->
<age_list >57 12 23 9 68</age_list ><!-- 列表类型的值以空白作为分隔符 -->
complexType
前面所提到的simpleType只能用来定义没有嵌套的元素,如果需要用到嵌套,就需要complexType来定义,简单类型的元素只包含文本值,没有子元素或属性。复杂类型的元素可以包含子元素、属性,或混合内容(文本和子元素混合)。
和simpleType的定义一样,可以在element内定义,也可以单独定义引用使用。
<xs:element name="person">
<xs:complexType>
<xs:sequence>
<xs:element name="firstName" type="xs:string"/>
<xs:element name="lastName" type="xs:string"/>
<xs:element name="age" type="xs:integer"/>
</xs:sequence>
<xs:attribute name="id" type="xs:integer" use="required"/>
</xs:complexType>
</xs:element>
<!-- OR -->
<xs:complexType name="PersonType">
<xs:sequence>
<xs:element name="firstName" type="xs:string"/>
<xs:element name="lastName" type="xs:string"/>
<xs:element name="age" type="xs:integer"/>
</xs:sequence>
<xs:attribute name="id" type="xs:integer" use="required"/>
</xs:complexType>
<xs:element name="person" type="PersonType"/>
complexType的子元素结构可以使用 sequence、choice 或 all 结构化
sequence:子元素必须按定义的顺序出现。choice:子元素中只能选择一个。all:子元素可以无序出现,每个子元素最多只能出现一次。
attribute定义元素属性,属性可以是可选(默认)、必需或带默认值
<xs:complexType>
<xs:attribute name="status" type="xs:string" default="active"/>
</xs:complexType>
mixed允许元素既包含文本又包含子元素
<xs:complexType name="detail_type" mixed="true">
<xs:sequence>
<xs:element name="note" type="xs:string"/>
</xs:sequence>
</xs:complexType>
<xs:element name="description" type="detail_type" />
<!-- XML -->
<description>
这是一些<note>这是另外一些</note>
</description>
group元素组和属性组用于定义和复用一组元素或属性。这种机制有助于减少冗余,提高模式的可维护性。【了解一下就行,不用这个也能写出来,和Python定义方法一样】
命名空间
命名空间(Namespace) 是一种解决命名冲突的方法,尤其是在一个文档中使用多个来源的元素和属性时。命名空间通过为每个元素或属性分配一个唯一的标识符(URI)来区分相同名称的元素或属性,确保它们具有独特性。
<!-- 默认命名空间 无前缀 element 元素属于 http://example.com/ns1 命名空间 -->
<root xmlns="http://example.com/ns1">
<element>Content</element>
</root>
<!-- html:table 属于 HTML 命名空间,svg:svg 属于 SVG 命名空间 -->
<root xmlns:html="http://www.w3.org/TR/html4/"
xmlns:svg="http://www.w3.org/2000/svg">
<html:table>
<html:tr>
<html:td>HTML Table Cell</html:td>
</html:tr>
</html:table>
<svg:svg width="100" height="100">
<svg:circle cx="50" cy="50" r="40" stroke="black" fill="red"/>
</svg:svg>
</root>
在xsd中使用targetNamespace来绑定命名空间
<!-- xsd -->
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://example.com/book"
xmlns="http://example.com/book"
elementFormDefault="qualified">
<xs:element name="book">
<xs:complexType>
<xs:sequence>
<xs:element name="title" type="xs:string"/>
<xs:element name="author" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
<!-- xml -->
<book xmlns="http://example.com/book">
<title>XML Guide</title>
<author>John Doe</author>
</book>
targetNamespace="http://example.com/book"将该模式绑定到命名空间,可以避免命名冲突elementFormDefault="qualified"要求所有元素都声明命名空间
rdf
基本思想
通过在XML中引用RDF,可以将XML的解析过程与解释过程相结合。也就是说,RDF可以帮助解析器在阅读XML的同时,获得XML所要表达的主题和对象,并可以根据它们的关系进行推理,从而做出基于语义的判断
RDF基本思想:被描述的事物具有一些属性(properties),这些属性各有其值(values);对资源的描述可以通过对它作出指定了上述属性及值的陈述(statement)来进行。
核心概念
资源:资源是任何可以唯一标识的对象或概念,通常使用URI来唯一标识
- 一个网页:
http://example.com/about - 一个实体:
http://example.com/person/JohnDoe
三元组:SPO,主谓宾
John is the author of Book1
<http://example.com/John> <http://example.com/isAuthorOf> <http://example.com/Book1> .
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.com/">
<rdf:Description rdf:about="http://example.com/John">
<ex:isAuthorOf rdf:resource="http://example.com/Book1"/>
</rdf:Description>
</rdf:RDF>
图模型:主语和宾语是节点,谓语是连接这些节点的有向边
RDF基本格式
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:prefix="namespace-URI">
<!-- RDF 描述 -->
</rdf:RDF>
描述一本书
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.com/schema#">
<rdf:Description rdf:about="http://example.com/book1">
<ex:title>RDF Guide</ex:title>
<ex:author>John Doe</ex:author>
<ex:publicationYear>2023</ex:publicationYear>
</rdf:Description>
</rdf:RDF>
嵌套描述作者
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.com/schema#">
<!-- 描述书 -->
<rdf:Description rdf:about="http://example.com/book1">
<ex:title>RDF Guide</ex:title>
<ex:author rdf:resource="http://example.com/person/JohnDoe"/>
</rdf:Description>
<!-- 描述作者 -->
<rdf:Description rdf:about="http://example.com/person/JohnDoe">
<ex:name>John Doe</ex:name>
<ex:profession>Writer</ex:profession>
</rdf:Description>
</rdf:RDF>
使用空节点,有时资源没有URI,例如描述一本书,作者的信息没有 URI,仅描述为名字和职业
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.com/schema#">
<rdf:Description rdf:about="http://example.com/book1">
<ex:title>RDF Guide</ex:title>
<ex:author>
<rdf:Description>
<ex:name>John Doe</ex:name>
<ex:profession>Writer</ex:profession>
</rdf:Description>
</ex:author>
</rdf:Description>
</rdf:RDF>
RDF/XML进阶
rdf:type可以用来定义某个资源属于某个类
<rdf:Description rdf:about="资源URI">
<rdf:type rdf:resource="类URI"/>
</rdf:Description>
xml:base基准URI应用于值为IRIs的所有RDF/XML属性,例如rdf:about、rdf:resource、rdf:ID、rdf:datatype等,假设我们描述一个人 John 和一本书 RDF Guide,URI 分别为 http://example.com/person/John 和 http://example.com/#RDFGuide
<rdf:RDF xml:base="http://example.com/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.com/schema#">
<rdf:Description rdf:about="person/John">
<ex:name>John</ex:name>
</rdf:Description>
<rdf:Description rdf:ID="RDFGuide">被解析为http://example.com/#RDFGuide
<ex:title>RDF Guide</ex:title>
</rdf:Description>
</rdf:RDF>
rdf:Bag、rdf:Seq 和 rdf:Alt 是三种用于表示集合(容器)的类型
| 容器类型 | 顺序 | 重复 | 应用场景 |
|---|---|---|---|
rdf:Bag |
无序 | 允许 | 表示无序集合(如作者列表) |
rdf:Seq |
有序 | 允许 | 表示有序集合(如章节、步骤) |
rdf:Alt |
可选 | 允许 | 表示可选集合(如多语言版本) |
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="http://example.com/book1">
<dc:creator>
<rdf:Bag>
<rdf:li>John Doe</rdf:li>
<rdf:li>Jane Smith</rdf:li>
<rdf:li>John Doe</rdf:li> <!-- 成员可以重复 -->
</rdf:Bag>
</dc:creator>
</rdf:Description>
</rdf:RDF>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]> 是一个声明部分,在文档中,可以用 &xsd; 引用这个实体,代替完整的命名空间 URI
<!DOCTYPE rdf:RDF [
<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">
]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.com/schema#">
<rdf:Description rdf:about="http://example.com/resource1">
<ex:age rdf:datatype="&xsd;integer">25</ex:age>
<ex:height rdf:datatype="&xsd;float">5.9</ex:height>
</rdf:Description>
</rdf:RDF>
RDF Schema
| 元素 | 描述 |
|---|---|
rdfs:Class |
定义一个类,类似于对象建模中的类或类别。 |
rdf:Property |
定义一个属性,用于描述资源之间的关系。 |
rdfs:subClassOf |
表示一个类是另一个类的子类,支持类的继承。 |
rdfs:domain |
指定属性的域(定义属性适用的资源类型)。 |
rdfs:range |
指定属性的范围(定义属性值的类型)。 |
rdfs:label |
为资源提供一个人类可读的标签。 |
rdfs:comment |
提供对资源或属性的注释。 |
这部分没啥说的,要会用RDF来描述实例
owl
本体
本体:是形式化的术语词汇表,通常覆盖一个特定领域并为某个用户社区所共享。它们通过描述本体中术语间的关系来给术语下定义。
-
类的声明:使用
<owl:Class rdf:about="类名"/>声明类。 -
类层次结构:通过
<rdfs:subClassOf>定义类之间的父子关系,此关系具有传递性和自反性。
<owl:Class rdf:about="Woman">
<rdfs:subClassOf rdf:resource="Person"/>
</owl:Class>
- 等价类:若两个类包含完全相同个体,则使用
<owl:equivalentClass>声明它们等价。
<owl:Class rdf:about="Woman">
<rdfs:subClassOf rdf:resource="Person"/>
</owl:Class>
- 类不相交:使用
<owl:AllDisjointClasses>和<owl:disjointWith>声明类之间不相容,即不相交。
<owl:Class rdf:about="Man">
<owl:disjointWith rdf:resource="Woman"/>
</owl:Class>
后面高级类关系不考,同样也要会描述
知识图谱
概念和如何构建知识图谱
知识图谱(Knowledge Graph)本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。通俗地讲,知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络。
主要的构建和应用技术
实体识别:从文本中发现命名实体,最典型的是人名、地名、机构名三类实体
关系抽取:抽取出实体与实体之间的关系
知识表示与存储,往往将知识图谱作为复杂的网络进行存储,网络的每个节点带有实体标签,每条边带有关系标签。
知识图谱的主要应用有:实体链接、查询理解、自动问答、文档表示
练习
手写出以下要求的代码,给出一些必要代码
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
</xs:schema>
<!-- 引用xsd 无命名空间 noNamespaceSchemaLocation -->
<root xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="name.xsd">
</root>
<!-- 引用有命名空间 -->
<root xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.example.org/schema"
xsi:schemaLocation="http://www.example.org/schema file.xsd">
</root>
<!-- RDF -->
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:prefix="namespace-URI">
</rdf:RDF>
XML 相关题目
- XML 基础知识
- 设计一个 XML 文档,描述一本书的基本信息(如书名、作者、出版日期、ISBN)。
- 创建一个 XML 文档,表示一个学校的课程信息,包括课程名称、教师、学分、学生列表。
- XML Schema (XSD)
- 编写一个 XML Schema (XSD) 文件,验证学生成绩单的结构。每个成绩单包含学生姓名、学号、课程和成绩。
- 创建一个 XSD 文件来验证一个产品目录,其中包括产品名称、描述、价格、数量等字段。
RDF 相关题目
-
RDF 基础
-
使用 RDF/XML 编写一个描述图书的 RDF 数据集。每本书应包括书名、作者、出版年份、ISBN 等信息。
-
定义一个 RDF 图谱,表示电影的基本信息(如电影名、导演、演员、发行年份),并包含一些样例数据。
-
RDFS 和类定义
-
使用 RDFS 定义一个 RDF 本体,表示动物分类信息。包括
Animal类及其子类(如Mammal,Bird),并定义每个类的相关属性(如hasHabitat,hasLegs)。 -
定义一个 RDF 类
Person,并为其添加属性hasAge和hasAddress,表示一个人的年龄和地址。 -
RDF 属性和实例化
-
使用 RDF/XML 语法定义一个资源
John,并为其指定类型为Person,同时添加属性hasAge(年龄为 30)。 -
使用 RDF/XML 创建一个实例
Eagle,类型为Bird,并使用hasHabitat属性将其栖息地设置为“山脉”。 -
OWL 本体与推理
- 使用 OWL 定义一个表示“公司”的本体,其中包括
Employee类、Manager类(Employee的子类),以及相关属性worksFor(员工与公司之间的关系)。 - 设计一个 OWL 本体,表示“医生”和“病人”之间的关系。医生和病人之间有一个
treats属性。使用推理引擎推导出某个病人的医生。